
第八章 模式识别
模式识别是认知心理学近年来在知觉领域中研究得比较多的。模式识别就是对刺激模式的辩别与确认。模式识别依赖于人脑对信息的复杂加工。要识别一个模式,感知到的信息必须与长时记忆中的信息进行匹配。当模式的感觉特征与记忆中的有关知识相匹配时,这个模式便被识别出来。
第一节 模式识别的一般概念
一、模式识别的概念
“模式”是由若干个元素集合在一起组成的一种结构。因此,一个物体、图象、语音、字符或人脸等等,都可以认为是一个模式,因为它们都是由若干个元素按照一定的关系集合在一起组成的。所以,通俗地讲,模式也就是我们周围世界中具有某种结构的各种客体,包括人在内。当然,一个较为复杂的模式,往往可以分成若干部分,而这些部分本身也是由若干个元素按一定的关系组成的一种结构。所以,这些部分就叫做“子模式”。“模式识别”是人们把输入刺激(模式)的信息与长时记忆中的有关信息进行匹配,并辨认出该刺激属于什么范畴的过程。因此,对物体、图象、语音或字符等等的识别,都可称之为模式识别。
在一般的认知模型中,我们可以看到,要识别一个模式,感知到的信息必须与长时记忆中的信息进行匹配。前一类信息来自于当时出现的某个刺激(模式);而后一类信息却不同,它是先前获得的、有关这类刺激的知识。当模式的感觉特征与先前获得的有关知识相匹配的时候,我们就说这个模式被识别了。在这个时候,人们往往会给刺激一个名称。所以,一般地讲,模式识别是对刺激“命名”,即给刺激一个名称。例如,在一定的位置上,给出一个由三条线(一/\)组成的刺激,人们就可能说这是一个“大”字。在这种情况下,人识别一个刺激的同时,也对该刺激指定了一个名称。当然,这不是说,模式识别总是意味着要对刺激命名。有时候,我们可以识别一个模式,但不必要(或不能)给它命名。
比如说,我们识别出一张脸是熟悉的,或者,某种气味可能使我们想起在什么地方闻到过,但没有把它们与某个确定的概念联系起来。
二、模式识别的简单模型
图8—1是简单情境下的模式识别的一个模型。它指明了,模式识别的任何一种模型或理论,应该包括哪些基本的内容。这里规定的情境是简单的,只是一个孤立的刺激瞬时出现,然后又很快消失。但是,在实际生活中,大多数自然而然地发生的刺激,都出现在一种有意义的前后和左右的关系中。这种有意义的关系,对人识别某个刺激来说,是非常重要的。
从图8—1中可以看出,对一个模式的识别,需要利用两种记忆。一是感觉存储,它主要存储输入的感觉信息;二是长时记忆,它保存着与上述输入信息进行匹配的、过去获得的关于各种事物的记忆编码。同时,对一个模式的识别。要使用三种基本过程。这些过程分别叫做“分析”、“比较”、和“决策”。
1.分析
识别过程的第一个阶段是分析,即把信息从感觉存储中抽取
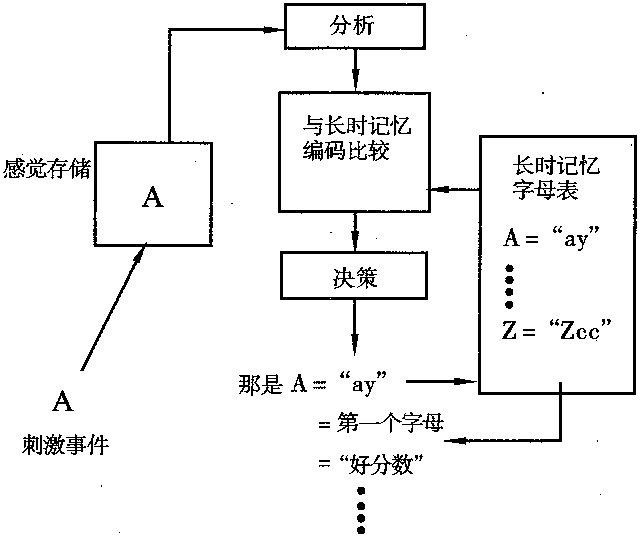
图8—1模式识别的基本组成部分
2.比较
在第二个阶段即比较过程中,分析阶段抽取出来的信息,与长时记忆中已有的各种信息进行比较。这意味着,长时记忆中的各种信息,必须处于一种当前刺激的信息能够跟它进行比较的状态。也就是说,长时记忆中存储的关于各种事物的记忆编码,必须与从实际刺激中抽取出来的信息是类似的。或者说,它必须描述了从实际刺激中抽取出来的信息。
3.决策
在刺激信息与长时记忆中的各种记忆编码进行比较以后,究竞哪一个记忆编码提供了最好的匹配,需要作出判定。这就是决策过程所要做的事情。决策过程确定了识别系统的输出。模式被识别为相应于获得最佳匹配的记忆编码。
由此可见,即使在图8一l这种简化的模型中,模式识别也要经历几个阶段。只有当刺激的信息经历了所有这几个阶段以后,才能够说这个模式被识别了。如果关于一个刺激的信息经历了分析和比较阶段的加工,但过程却停顿下来了,识别系统对它不再作进一步的加工,或不能作出决策。在这种情况下,对模式的识别是不完全的,因为关于刺激的信息没有成功地经历模式识别的三个基本阶段。对模式的完全识别,这是第三个阶段即决策过程的产物。
某个模式一旦被识别以后,就会从长时记忆中诱发出与这个模式有关的更多的信息。比如说,一旦我们识别了刺激“A”,我们会由此而想到,它是英文字母表的第一个字母;或者,它是大家想要得到的一个好的分数等级,如此等等。
三、模式识别的意义
经过模式识别以后,关于刺激的粗糙的、原始状态的信息(如视觉形状),就转换成某种对人来说有意义的东西。模式识别在人类适应环境和改造环境中是非常重要的。假如说,一个人不能把输入的刺激信息正确地识别为一只“虎”,而是错误地把它归结为一只“猫”,那么,他就会对刺激作出绝然不同的反应。人的识别系统一旦出现缺陷,就会危及到人的生存。
科学家们力图研制出一种能象人类那样进行模式识别的机器,以代替人的繁重的劳动。这方面的工作已取得了一定的成绩。例如,科学家们已经研制出了光学文字识别机,用它代替人的一部分识别任务。
第二节 模式识别的理论
为了对人的模式识别作进一步的描述,人们对模式识别时使用的记忆编码及这些编码的使用等问题,作了一些探讨,提出了三种假设。这三种假设是:模板假设、原型假设和特征假设。
一、模板假设
1.什么是“模板假说”
前面曾指出,存储在长时记忆中的,在模式识别中要使用的记忆编码,必须类似于(或描述)相应的刺激,否则就无法用来进行比较,识别过程就会产生障碍。有一种假设认为,记忆编码,与相应的刺激之间是非常一致的;长时记忆中的编码,是该刺激的某种缩小了的拷贝(或模板、样板)。它们之间存在着一对一的对应关系。也就是说,对我们识别的每一个刺激来说,都有一个用来与它进行匹配的内部拷贝。这就是“模板(template)假说”的内容。根据这个假设,刺激的感觉形象经过第一阶段的分析后,基本上不变地被传送到第二阶段去加工。在这个阶段上,刺激的感觉形象与长讨记忆中的许多模板进行比较。通过比较,某一个模板可能与刺激的感觉形象匹配得最好。于是,决策过程把这一获得最佳匹配的模板选出来。这时,模式也就被识别了。比如说,我们识别一个“上”字。根据模板假设的规定,在长时记忆中有它的一个拷贝。每当“上”字作为一个刺激呈现时,它的视觉形象就与长时记忆中的许多模板进行比较。比较结果,记忆中关于“上”字的拷贝获得最好的匹配。因此,人就把这个模式识别为“上”。
这种模板假设看起来过于朴素和简单化,所以,用它来作为模式识别的理论基础有些不太合适。因为按照这个假设,为了识别每一个在形状、大小或方位上稍有变化的字,在长时记忆中就得具备一个相应的模板。这就是说,改变一下字的大小或形状,就需要一个不同的模板;如果把“上”稍微旋转一下,产生一个仍然可以识别的上字,则又需另一个摸板,如此等等。如果对这些大小、形状和方位不同的刺激不具备相应的模板,那么,模式识别就会陷入困境。

图8—2(a)模板(浅色)不能成功地与字母(深黑色)相匹配;(b)发生错误的匹配
图8—2(a)表明,当字母A(深黑色)的大小、方位和位置有变化时,模板(浅色)就不能成功地得到匹配;图8—2(b)则表示发生错误匹配的情况。当字母的形状发生变化时,A模板可能与字母R获得较好的匹配,而与字母A的匹配程度反而较差。同样,对一个倾斜的字母A来说,R模板可能会获得比A模板更好的匹配。根据模板假设,当倾斜的A出现时,我们会错误地把它识别为R,而不是字母A。如果要避免上述这种情况,我们就需要无限数量的模板。毫无疑问,这将会超出一个人的长时记忆的能力。
2.模板假设的修正
要使模板假设能比较满意地解释人的模式识别过程,必须要作适当的修正补充。
有一种修正意见,主张在模型中加上一个预处理过程。这个过程发生在比较阶段之前。起一种“净化”(cle|皿up)的作用。它能使刺激的感觉形象进人一种标准的大小和方位。由于这一过程缩减了刺激形象的不规则性,使它进入一种比较正常的形式,所以,人们把它称之为对刺激的感觉形象的“标准化”(normaIizing)。例如,若有这样一个刺激,那么,在它与模板进行比较之前,“标准化”过程就要把它的位置重新摆正,把尺寸缩小,以及把它右边变曲的一笔弄直。这样一个发生在比较阶段之前的预处理过程,就会大大地减少识别字母A所需要的模板数量。
但是,加上这样一个预处理过程,可能会出现一个逻辑上的毛病。要纠正刺激形象的方位和大小,就必须要知道合适的方位和大小是什么样的。这就等于说,“已经”知道刺激相当于什么模式了。例如,一个看起来象“目”这样的刺激,调正它的方位时,若把它横下来则象“四”,把它坚起来则象“目”。为了知道哪个方位是正确的,就必须首先确定它是哪个字,但是,这乃是模式识别系统要做的事情,而不是比较之前某个加工过程要完成的事情。它应该是识别的结果,而不是识别的前提。
当然,要处理这个逻辑上的问题,也是不可能的。一则,如果明显偏离标准方位(如“上”偏离成“丁”),其结果或许会形成一个确实不能识别的刺激。这就是说,当识别系统事实上不能处理这个刺激时,也就没有理由要求比较过程之前的“标准化”过程必须能够处理它。其次,正如前面已经指出的,被识别的刺激通常总是出现在某种有意义的关系中。这种关系能够指明一个刺激的合适的形状和方位应该是什么样的,从而会有助于这个标准化过程。
二、原型假设
1.“原型”的概念
“标准化”过程可以帮助处理模板假设的不足,但并不能完全解释人的识别问题。事实上,尽管刺激并不是出现在某种特定的前后关系中,但当它们的大小或形状有变化时,我们仍然能够识别它们。为了解释这种现象,人们就提出了“原型”(prototype)这个概念。原型与模板不同,它不是某个刺激的内部拷贝。原型是表示某类客体之基本成分的一种抽象的形式。例如,飞机的原型是有两个翅膀附在上面的一个长简;狗的原型大致是一个有二尺高、四条腿、二只眼睛、尖的牙齿、较长的鼻子和身上长毛的动物形象。因此,原型是从某类客体的各个具体经验中抽取出来的。某一范畴的客体的原型,代表了这个范畴中所有客体的集中趋势。
模式识别的原型假设认为,存储在长时记忆中的东西,不是模板,而是原型,原型与输入刺激之间的关系,不是一对一的关系。因此,人在识别模式时,尽管同一范畴的各个模式之间有形状或大小等方面的变化,该范畴的原型也能与它们相匹配。在人们的长时记忆中,存储着各种范畴的原型,象飞机、猫、狗或字母A的原型等等。人们依靠这些原型,可以有效地识别属于这些范畴的各个成员。每当一个新的刺激呈现时,它就与原型进行比较,并且只需要得到一种近似的匹配,而不是一种确切的、模板式的匹配。当刺激的感觉形象与某个原型获得最近似的匹配时,人们就确认这个刺激属于该原型代表的范畴。原型假设是对模板假设的改进,因为它表明了,即使长时记忆的编码不是某种刺激的确切的复写,人也能识别这个刺激。
2.支持原型假设的实验
原型究意是否存在?有一些实验表明,它们是存在的。J.J弗兰克斯(J.J.Franks)和J.D.布兰斯福德(J.D.Bransford)做过有关实验,结果支持了原型假设。他们利用一些几何图形,如三角形、圆形和星形等,组合成某种结构图。这种结构图作为原型模式,如图8_3左边第一个结构图。然后,对原型作某种(或几种)变换,从而构成该原型的各种变形,如图8—3右边的四个结构图。这种变换可能是:左右位置变换(第一个变形);内外位置变换(第二个变形,方块移至三角形里边);删掉一个几何图形(第三个变形,删掉了一个正方形);而在第四个变形中,包括了前面三种变换。他们先让被试看一些属于变形的模式,然后再给被试一个测验。在测验中,给被试呈现一系列模式。其中一些是被试曾见过的变形,另一些是没有见过的新变形,以及原型本身。针对每一个呈现给被试看的图形,要求他确认以前是否见过这个图形。结果表明,被试对原型图形的反应,往往比较肯定地认为是以前见过的。事实上,在实验的第一阶段中,并没有给被试看过这些原型图形。而对于那些变形,不管是以前见过的或是没有见过的,被试同样地认为见过的可能性较小。对于那些由几次变换而产生的变形,由于其偏离原型(与原型图形的差别)较大,被试认为见过的可能性就更小。
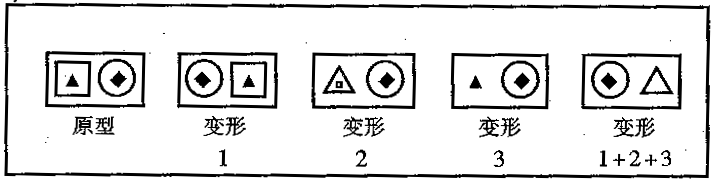
图8—3弗兰克斯和布兰斯福德在实验中使用的原型及其变形的例子
这一实验表明,被试从一组有关模式的经验中,抽取出了这组模式的原型。同时,也可以看到,被试在识别那些变形时,利用了这个原型,是把它们与原型作比较的。这种实验结果支持了原型假设。
三、特征假设
1.什么是“特征假设”
前面说过,每一个模式(或客体)都是由若干个元素按照一定的关系结合在一起构成的。这就意味着,任何模式都可以分解成一些基本的成分或特征。例如,可以把英文字母看成是由垂直线、水平线等这样一些基本特征组成的。PH林德赛和D_A.诺曼(PH.Ldndsay和D.A.Norm~m)把构成英文字母的特征分成七种,它们是:垂直线、水平线、斜线、直角、锐角、连续曲线和不连续曲线。表8-1列出了每个字母具有上述哪些特征的详纽隋况。从表中可以看出,字母A包含有一条水平线和二条斜线;字母T包含一条水平线、一条垂直线和两个直角;而字母s则包含两条不连续曲线。事实上,不连续曲线还可以分成两种,一是c曲线(即“c”形曲线),另一是D曲线(“D”形曲线)..特征假设认为,各
种刺激在长时记忆巾的编码,是一张表,表上登记着该种刺激所具有的那些特征的名称。这种表叫做“特征表”。人的识别系统在接受了一个输人刺激的信息以后,首先对它的特征进行分析,找出输入刺激具有哪些特征,然后把它们与长时记忆中的各种特征表进行比较。一旦长时记忆中的某张特征表与刺激的特征获得最佳的匹配,这个刺激也就被识别了。
特征假设确有它的优点。如果人们能对一组相当大数量的模式,抽取出少量的一些特征,而且,用这少量特征足以描述这大量的模式(例如,用一些基本特征来描述人类的文字),那么,识别系统需要加以存储和处理的东西,就将大大减少。
但是,把特征假设用来解释模式识别时,也会碰到一些问题。有时候,两个模式的差别只是有或没有某一个特征,如E和F两个字母。字母E下面的一横,在F中是没有的。但长时记忆中的两张特征表(E特征表和F特征表),都可以与字母F相匹配。因为F的每个特征,在E特征表和F特征表中,都是存在的。在这种情况下,如何进行决策,以达到正确的识别,这似乎是一个问题。
表8—1 构成英文字母的各种特征
2.“鬼域”模型
特性假设的‘利r形式叫做“鬼域”(pandemonium)。这是由O.G.塞尔弗里奇(O.G.Selfridge)提出来的。煳8-4描述了鬼域模型的概貌。这个模型表明,识别一个模式要通过几个阶段或层次。在每一层次上,都有一些小鬼(demon),它们肩负着不同的任务,起着不同的作用。“映象鬼”在第一个层次上,它要完成的工作,是把刺激作为感觉事件记录下来。然后,“特征鬼”在第二个层次上对刺激的感觉映象进行分析,把它分解成各种特征成分。每一个“特征鬼”代表某一个特征,如一条直线或一个直角。并且,它必须就输入刺激中是否存在它所代表的特征作出明确的反应。“认知鬼”则相当于前面所说的特征表。每一个“认知鬼”代表某一种模式。“认知鬼”的任务是对“特性鬼”进行观察,每当由特征分析的结果表明它可能是一个侯选者时,就尽可能大声地叫喊或发出信号。也就是说,“认知鬼”注视着发出反应的“特征鬼”及其数量。如果它发现许多作出反应的“特征鬼”是属于自己的特征,就大声地叫喊;否则,叫喊的声音就小,或者不作声。“决策鬼”在更深的一个层次上。它的工作是要确定在那些正叫喊着的“认知鬼”中,哪一个叫喊的声音最大(决策过程),从而认知这个模式。

图8-4模式识别的鬼域模型
有不少事实证明,特征匹配是用于模式识别过程的。一些生理学的研究表明,视觉系统包含有专门化的细胞。它们的功能就是识别某种特定的特征。生理学家们(如D H.Hubel及J.YLettvln等人)发现,在青蛙、猫等动物的视觉系统中,有些神经细胞只是在视觉刺激的某种特征(如水平线、垂直线和移动着的点等)出现时才激活,即发生反应。生理学家们把这些功能专门化的神经细胞,称之为特征察觉器。例如,在青蛙视觉系统中,有一种特征察觉器仅对黑的、略呈圆形的、动的刺激发生反应。当这样的目标进入青蛙的视野时,相应的特征察觉器就开始活动。目标离青蛙越近,察觉器的活动也越强烈,最后引起视觉和运动联合行动,伸出舌头,捉住目标。这种目标往往是一些昆虫,所以,这种特
征察觉器也叫做昆虫察觉器。
人们推测,人也可能有这样的细胞。而且,这些细胞的激活,似乎不依赖于特殊的刺激特征,如长度。因此,它们好象可以察觉比较抽象的特征,如一个特定角度上的任意长的线。所以,尽管模式在大小方面有各种变化,但人们也能够识别它们。
特性在模式识别中的作用,还有其他的一些根据。例如,小孩常常用同一名称来称呼印刷字母b和d。这可能反映了小孩不能精确区分视觉特征c曲线和。曲线,也就是说,不能区别只是在方位上有差别的视觉特性。如果视觉刺激呈现得很快,那么,在成年人身上也会出现这种情况,这就是所谓的“混同”(confusion)现象。例如,在视觉上把一个字母(如Q)看成另一个字母(如D)。这种现象之所以发生,是因为这两个刺激共有一些视觉特征。在听觉上也有类似的现象。两个音节在发音特性方面愈接近,它们就愈容易混同。例如,被试很容易把B误听为D。这是因为B和D在听觉上有类似的特征。所有这些情况表明,模式的特征在识别中确实是起作用的。
第三节 模式识别的比较过程
一、串行加工
一个输入模式的信息必须与大量的记忆编码进行比较,然后才能选出那个与模式匹配得最好的编码(模板、原型或特征表)。模式识别的这一比较过程是以什么方式进行的?一种可能的方式是串行加工,即输入的模式与长时记忆中的编码一个接着一个地进行比较,然后再确定与哪一个编码匹配得最好,就拿模板假设而论,在能够作出决策之前,输入模式或许要与长时记忆中的全部模板进行比较。在长时记忆中存储的模板数量是很大的,所以,这种比较过程的任务将十分繁重。因此,如果人的识别系统在把输入刺激与长时记忆编码进行比较时,采用一个接着一个的串行加工方式,那末,为了识别某些模式,肯定会花很长的时间。可是,我们大家知道,人的模式识别往往是进行得很快的。所以,识别系统在把刺激与记忆编码进行比较时,在某种条件下并不是采用串行的加工方式。
二、平行加工
与串行加工相对应的另一个过程,叫做平行加工。“平行”来源于几何学的意义。是指二条或二条以上的线路并排地一起进行。平行加工恰好就是这个意思,在这里,就是指许多独立的比较同时进行。这就是说,在模式识别中,刺激可以同时地与许多内部记忆码进行比较,而整个过程所需的时间差不多就等于刺激与单个记忆码进行比较的时间。在刺激和记忆码进行比较时,识别系统如果采用平行加工的方式,那么,比较过程将会节省很多时间。
我们知道,在物理世界中,确有这样的平行加工。例如,我们拿一把频率未知的音叉,敲打它,使它嗡嗡地响,并把它放在一组频率已知的音叉旁边这时,该组音叉中的某一把音叉也开始嗡嗡地作响。这把音叉的频率与频率未知的音叉的频率是相匹配的。用这种办法,人们可以确定某个音叉的频率。在这里,被测音叉是同时地对着所有频率已知的音叉进行比较的,所以,这是一个平行的加工过程。
用平行加工的方式,识别就可以加快,因为许多操作可以同时进行,从而比串行加工节省时间。如果比较过程是平行的(并且假定系统有足够的容量来同时执行所有这些操作),那么,输入模式可以与每一个现存的长时记忆码进行比较,这在理论上是可能的。
思考题
1.简述模式识别的概念及其三个阶段。
2.简述原型假设与模板假设的区别。
3.简述特征假设和“鬼域”模型。
4.说明串行加工和平行加工的概念。